

Um kundenzentrisch zu personalisieren, brauchst du in deinem Data Management Scores, Kontroll-Parameter und eine übergreifende Berechnungslogik
Der Ton macht die Musik, heißt es. Stimmt aber nicht. Das Orchestrieren der vielen Töne und Klangquellen entscheidet, ob im Ohr des Zuhörers ein guter Song ankommt – oder Kakofonie. Und es wird noch komplizierter. Denn jedes Ohr, jeder Musikfreund, jede Kundin hat eigenen Vorlieben. Im Dialogmarketing eines datengetriebenen Unternehmens macht die Personalisierung und Automatisierung die Musik. Das Data Management hat eben auch die Aufgabe des Arrangeurs – Daten sind eminent wichtig, machen aber noch kein Marketing. Scoring-Modelle sorgen in Verbindung mit weiteren Kontroll-Parametern und Attributen aus dem Kundenprofil für eine gesamtheitliche Berechnungslogik, auf deren Basis deine Kommunikation kundenzentrisch ausgespielt wird. Also die richtige Botschaft die richtige Kundin, den richtigen Kunden erreicht und dabei ebenso effizient wie nachhaltig wirkungsvoll arbeitet. Lass uns mal ansehen, wie das funktioniert …
Die Scores und Kontroll-Parameter definieren
Es gilt, innerhalb deines Data Management zunächst die Kontroll-Parameter zu identifizieren, die für deine KundInnen und dein Geschäftsmodell über den Erfolg von Kommunikationsmaßnahmen entscheiden. Ein erfahrener Data Scientist wird hier ein Konzept entwickeln können, mit dem sich aussagekräftige und trennscharfe Scoring-Modelle erstellen und Kontroll-Parameter ableiten lassen. Diese Scores und Kontroll-Parameter sind dann relevant für die Steuerung aller Maßnahmen.
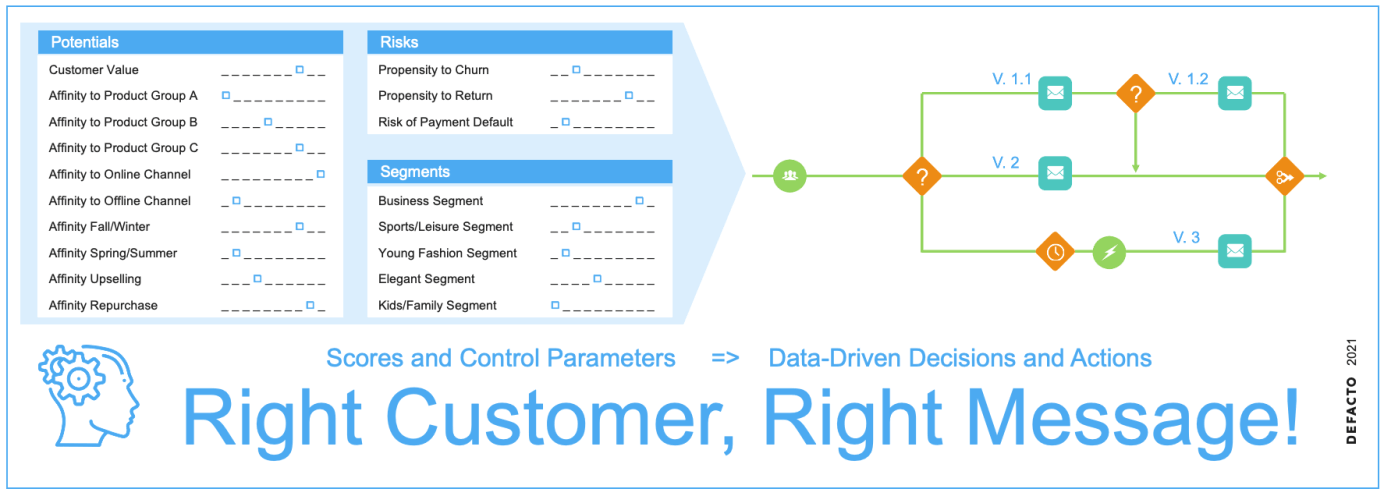
Scores und Kontroll-Parameter bilden die Grundlage für datengetriebene Entscheidungen und Maßnahmen – damit der richtige Kunde oder die richtige Kundin mit der für ihn/sie richtigen Botschaft beworben wird.
Use Cases auf Basis der Scores entwickeln
Im nächsten Schritt geht es um die Entwicklung von Maßnahmen, die sich für Automatisierung und Personalisierung eignen. Und die die Customer Experience positiv beeinflussen. Die Scorings deines Data Management sollten konzeptionell so ausgelegt sein, dass sie die geschäftsrelevanten Use Cases bestmöglich unterstützen – Erfahrung und Expertise helfen natürlich, um hier sowohl bewährte Standardmaßnahmen effizienter zu machen als auch neue Ansätze mit vielversprechendem Potential zu entwickeln.
Den methodischen Ansatz für die Scoring-Modelle beschreiben
Vor der Anwendung steht allerdings noch die Ausarbeitung eines methodischen Ansatzes mit seinen funktionalen Spezifikationen. Erst wenn dieser Ansatz steht, können die eigentlichen Scoring-Modelle für dein Data Management erstellt werden. Immer vorausgesetzt, dass du schon die geeignete analytische Umgebung dafür am Start hast – als Plattform für Predictive Analytics. Ein versierter Data Scientist kann schnell beurteilen, wie du hier aufgestellt bist.
Personalisierung und Automatisierung intelligent steuern
Daten liefern die Vorlage für kundenzentrisches, personalisiertes Marketing, das auf informierten, datengetriebenen Entscheidungen und – aus Effizienzgründen wohl als notwendig vorauszusetzen – automatisierten Use Cases beruht. Für die Intelligenz im Data Management sind Scoring-Modelle und eine Berechnungslogik wesentlich, welche quasi aus den vielen Tönen deinen Marketing-Hit arrangieren. Bei der Implementierung, aber auch beim Monitoring und bei der Qualitätssicherung, solltest du eng mit erfahrenen Data Scientists aus deinem Unternehmen zusammenarbeiten oder dir diese Expertise dafür temporär ins Haus holen.
Was ist eigentlich ein Scoring-Modell?
Ein Scoring-Modell bildet letztendlich einen funktionalen Zusammenhang zwischen einer gewünschten Zielgröße und einer Menge von verfügbaren Einflussgrößen ab. Prominente Beispiele für Zielgrößen sind die Wiederkaufwahrscheinlichkeit eines Neukunden, die Abwanderungswahrscheinlichkeit eines Bestandskunden, die Kaufwahrscheinlichkeit für eine bestimmte Produktgruppe, die Affinität für Preisnachlässe oder die Präferenz für einen bestimmten Kaufkanal. Derartige Zielgrößen werden auch als Scores bezeichnet, da ihr Wertebereich in der Regel einer normierten Punkteskala entspricht. Als potenzielle Einflussgrößen kommen soziodemografische Merkmale und konsumbezogene Attribute in Frage, aber auch Merkmale aus dem Customer Service, dem Zahlungsverhalten und dem Web Tracking. Um den funktionalen Zusammenhang zu ermitteln, kann man auf bewährte Lernverfahren zur Bildung von Modellen zurückgreifen, die anhand historischer Daten trainiert werden. Eine wesentliche Voraussetzung für die Erstellung von Modellen ist also immer die Sammlung und Bereitstellung von möglichst qualitativ hochwertigen (d.h. korrekten, vollständigen und in sich stimmigen) Daten. Nach dem Abschluss der Trainingsphase wird die Prognosegüte eines Modells auf der Basis unabhängiger Testdaten ermittelt. Wenn das Modell eine zufriedenstellende Prognosegüte erreicht, kann es in den operativen Betrieb überführt werden. In diesem Anwendungsmodus berechnet das Modell dann einen individuellen Zielwert (Score) für jeden Kunden, der sich für die Steuerung der Kundeninteraktion verwenden lässt.
Gerne unterstützen wir bei der Implementierung aller notwendigen Prozesse, um mit Scores und Kontroll-Parametern die Grundlage für datengetriebene Entscheidungen und Maßnahmen zu schaffen. Unsere Data Scientist begleiten dich dabei mit ihrer Erfahrung und klar definierten Deliverables. Vereinbare einen unverbindlichen Gesprächstermin mit uns.
Wenn du mehr News mehr zu Digitalisierung, CRM und Data Management erhalten möchtest, dann melde dich zu unserem Newsletter an.
Mehr Beiträge zum Thema Data Management:
Mit den richtigen Analytics-Tools Customer Insights gewinnen
Effizientes Data Management braucht relevante Daten
Aus Rohdaten umfassende Kundenprofile mit operationalisierbaren Attributen berechnen
Autor
 Thomas Plennert
Thomas Plennert
Executive Director Data Intelligence
DEFACTO GmbH
Tel. +49 151 1205 2965
thomas.plennert@defacto.de




